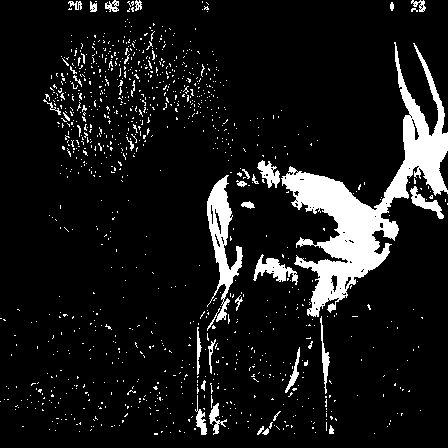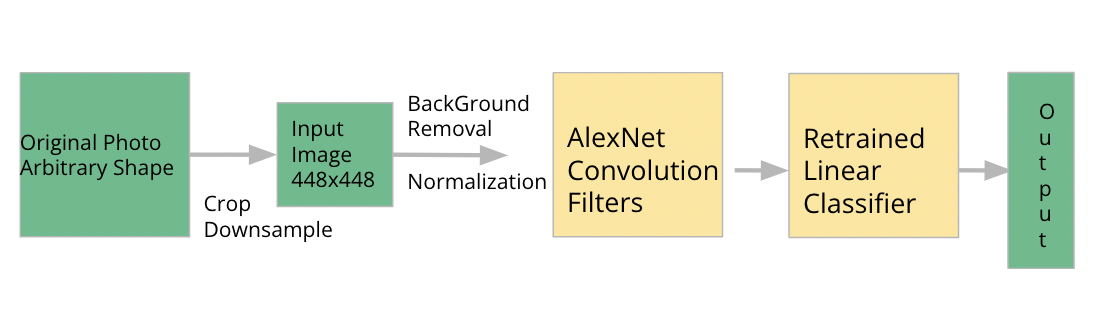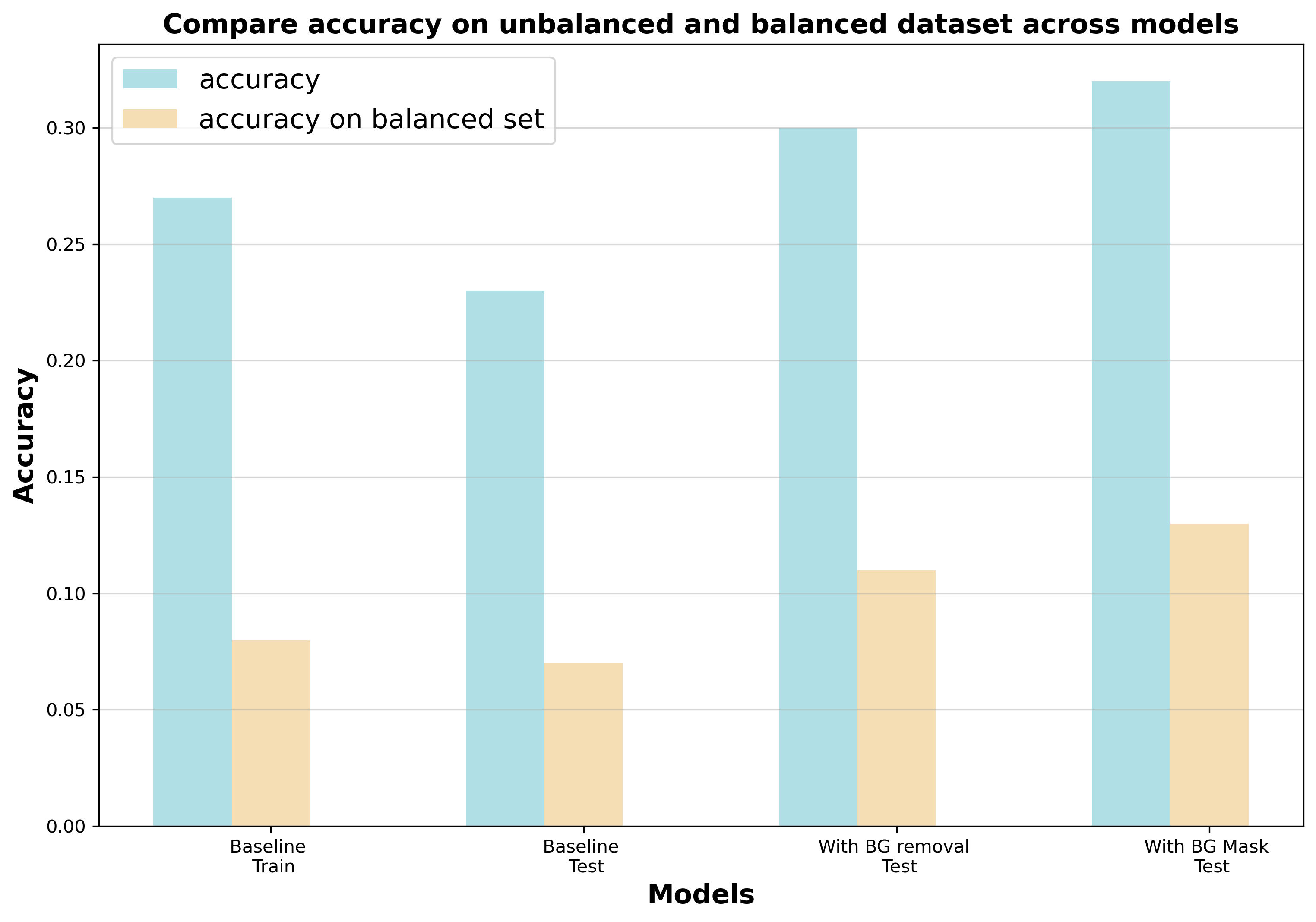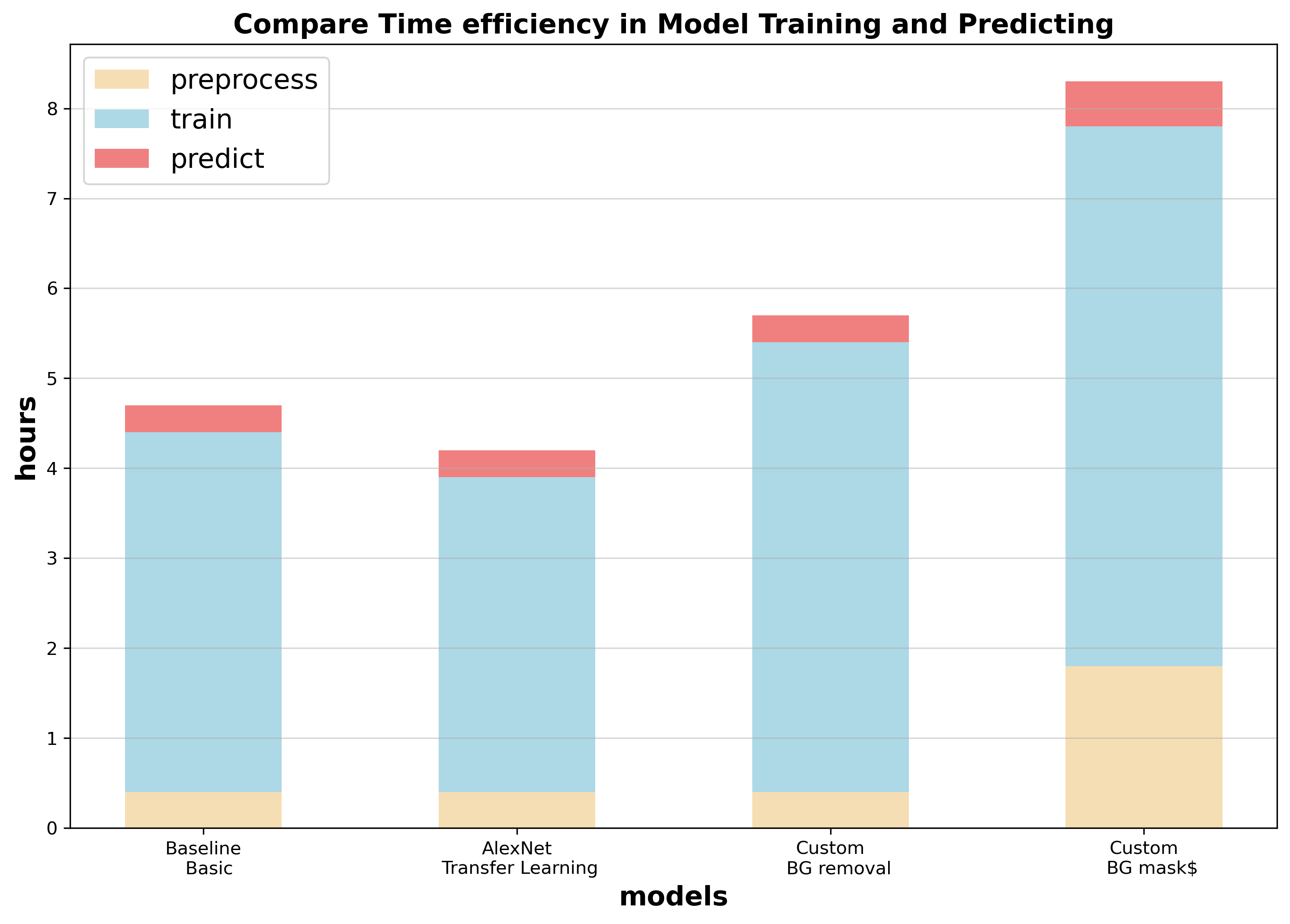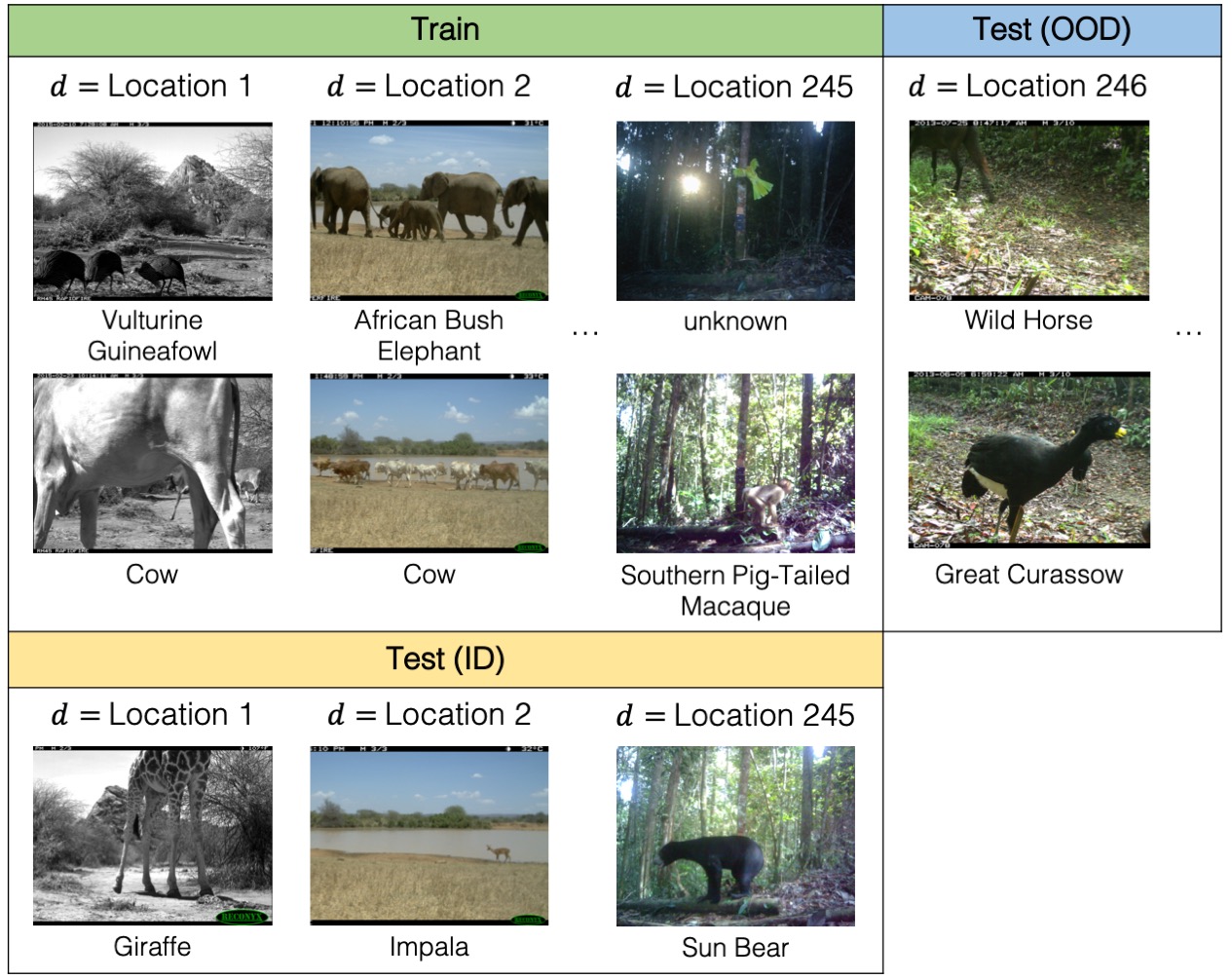


Background Removal
Background removal is a process that involves subtracting the background image of a location from the original image, resulting in an image that highlights the animal features in the photo. In the context of a domain adaptation problem, where models are trained on one set of camera trap photos and tested on another set, background removal can be used as a method to reduce variation between camera trap deployments. Since different camera traps can have vastly different backgrounds, removing the background from images ensures that the resulting images contain only animal features that are consistent across different camera traps.